中国信通院启动大模型系列标准编制工作
- 发布时间:2025-07-06
- 来源:搜狐新闻
2021年12月,国务院印发《“十四五”数字经济发展规划》,指出要增强关键技术创新能力,提高数字技术基础研发能力,加快创新技术的工程化和产业化。大规模预训练模型(以下简称“大模型”)作为人工智能新基建领域新兴并快速发展的热点方向之一,近年来参数规模和模型性能不断创出新高,逐步夯实人工智能技术底座,加速推进人工智能实用化、通用化和普惠化发展进程。
大模型丰富了深度学习、知识图谱等人工智能通用技术理论体系,并显著提升自然语言处理、计算机视觉、智能语音等领域技术的应用性能。然而,兼具调大参数、吃大数据、用大集群等特性的大模型,在以下问题越来越受到产业各方的关注:
一是多类别多场景的大模型导致技术评价难度提升。当前学术界和产业界发布的大模型多以公开榜单数据为主,缺乏科学精准的评估体系,难以反映大模型在千行百业复杂场景下的实际应用效果,不利于大模型研究和应用形成有效闭环。
二是技术能力和开发成本制约大模型的规模化落地。大模型在训练和推理环节不仅需要用户有较高的技术储备,也需要投入数以千万计的研发和软硬件成本,给中小型企业及应用方的技术复现、二次开发和系统部署造成极大的负担,严重阻碍大模型的工程化进程。
三是数据和算法安全制约了大模型的可信应用。一方面,大模型训练过程高度依赖海量无监督数据,存在数据源头追溯困难、数据内容合规评估复杂、数据所有权界定争议等问题。另一方面,大模型开发环节依靠人工经验进行调优,容易引入主观臆断、认知偏见、公平公正等问题。
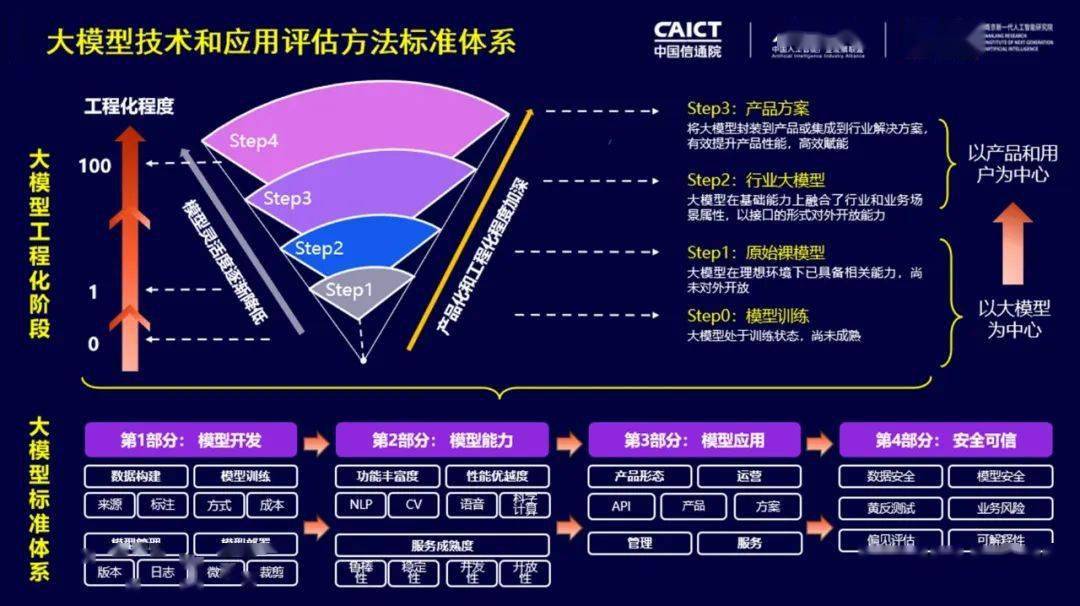
中国信息通信研究院(以下简称“中国信通院”)紧密跟踪大模型在技术能力、产业应用、安全可信等方面的产业需求,自2021年启动标准研究工作以来,联合技术供应方、方案集成方、应用需求方共同梳理大模型工程化重要实践阶段,明晰大模型发展痛点难点问题,形成大模型技术和应用评测标准体系。该标准体系对应大模型工程化四个阶段,即模型开发、模型能力、模型应用和安全可信,分别关注模型开发要素及训练过程、模型功能丰富度及性能优越度、模型管理部署及运营服务、模型的安全可信及风险偏见。目前,模型开发、模型能力两项标准已启动编制,正面向产学研用各方征集参编单位及专家。
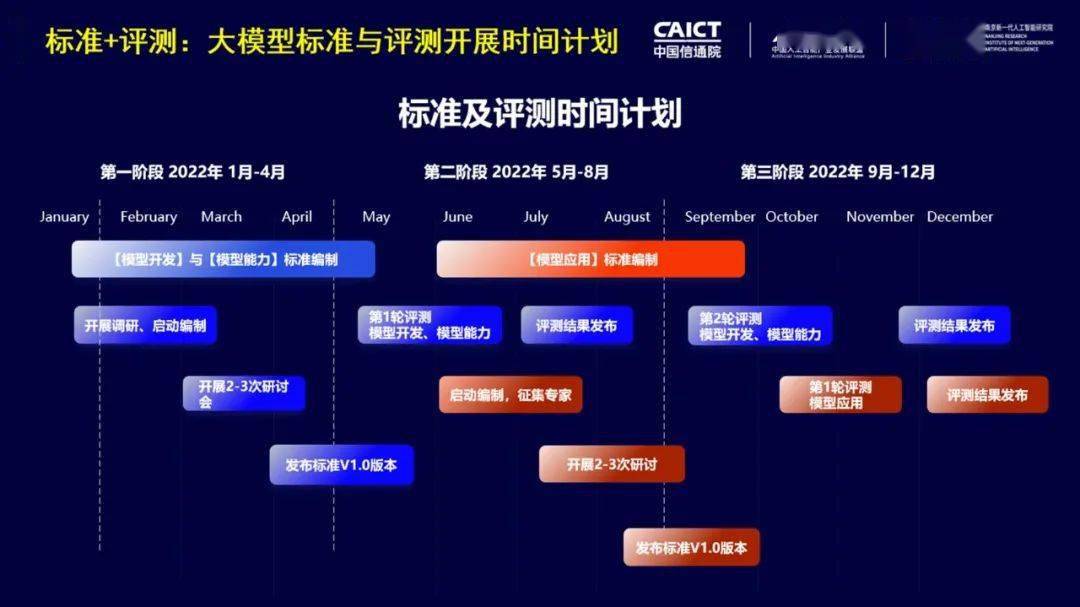
未来,中国信通院将继续紧密联合大模型产业各方搭建交流平台,建设和完善大模型技术和应用评估方法标准体系,全心助力我国大模型源头创新,全力助推大模型研究、开发、应用、部署、运营、管理、服务等工程化进程。
各方单位及专家如有意愿参与大模型系列标准制定和评估测试工作,请联系中国信通院云计算与大数据研究所。