谷歌、DeepMind发现大语言模型突现能力,可推动自然语言处理研究
- 发布时间:2025-07-15
- 来源:DeepTech深科技
关于 AI 未来发展的一个关键话题是,扩大规模是否会导致模型的质量产生较大变化。最近,来自谷歌研究院、斯坦福大学、北卡罗来纳大学教堂山分校和 DeepMind的一组研究人员给出了肯定答案。
他们的研究讨论了大语言模型的突现能力。突现可定义为一个系统中的定量变化导致行为中的定性变化。研究者在论文中解释称:“突现作为一种思想在物理学、生物学和计算机科学等领域早已被讨论过。具体来说,大语言模型的突现能力指的是,如果一种能力不存在于较小的模型中,但存在于较大的模型中,则该能力被视为突现能力。”
 (来源:Pixabay)
(来源:Pixabay)
6 月 15 日,相关论文以《大语言模型的突现能力》(Emergent Abilities of Large Language Models)为题提交在 arxiv 上。
近年来,语言模型对自然语言处理(Natural Language Processing,NLP)有着积极影响。研究人员表示:“目前,增加语言模型的规模可以在一系列下游 NLP 任务上获得更好的性能和样本效率。”并指出,突现的存在意味着增加规模可以进一步扩大语言模型的功能范围。
为了评估大语言模型的突现能力,研究人员利用了提示范式,其中预先训练的语言模型被赋予任务提示(例如,自然语言指令)并完成响应,而无需对其参数进行任何进一步的训练或参数梯度更新。
本次基准测试分为小样本提示任务和增强提示策略。小样本提示任务包括加法和减法等内容,以及数学、历史、法律等领域的语言理解。增强提示策略包括多步骤推理和指令跟踪等任务。
该研究评估了谷歌的 LaMDA、PaLM 和 OpenAI 的 GPT-3,以及 DeepMind 的 Gopher、Chinchilla 等的突现能力。
当通过缩放曲线(X 轴:模型规模,Y 轴:性能)可视化时,突现能力显示出一个清晰的模式:性能达到一定的规模临界阈值前是接近随机性能的,之后性能大幅增加。这种定性的变化也被称为相变(整体行为的巨大变化),这是通过检查小规模系统无法预见的。
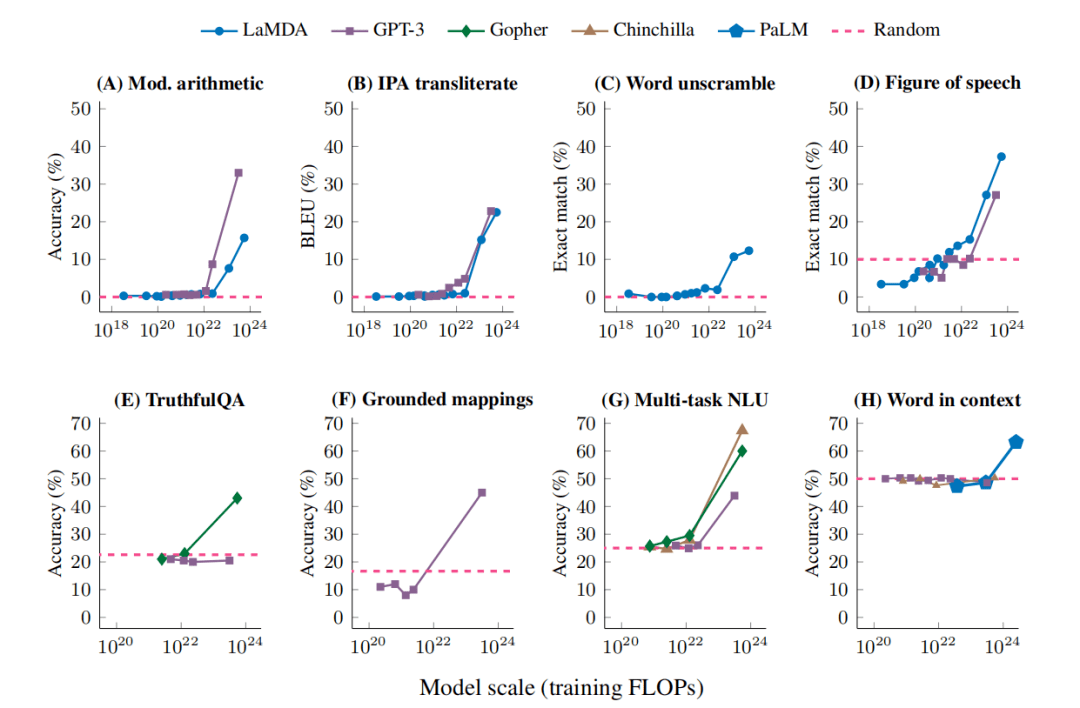 图 | 在小样本提示任务中出现的 8 个例子。每个点都是一个单独的模型(来源:arxiv)
图 | 在小样本提示任务中出现的 8 个例子。每个点都是一个单独的模型(来源:arxiv)
研究人员发现,在足够大的语言模型上进行评估时,才能观察到一系列突现能力。这不能简单地通过推断较小规模模型的性能来预测。总体含义是,进一步的扩展可能会赋予更大语言模型新的突现能力。语言模型目前不能完成的任务是导致未来突现产生的主要候选任务。例如,基准测试中有许多任务,即使是最大的 LaMDA 和 GPT-3 也无法实现高于随机的性能。
据了解,语言模型主要沿着三个因素进行扩展:计算量、模型参数的数量和训练数据集的大小。本次研究的重点是语言模型的计算量(往往也有更多的参数),没有针对训练数据集的大小做相应研究,因为许多语言模型对所有模型大小使用固定数量的训练示例。
虽然仅关注训练计算和模型大小,但没有一个单一的代理能够充分捕获规模的所有方面。因此,研究人员指出,将突现视为许多相关变量的函数可能是明智的。
图 | 大语言模型的突现能力列表和这些能力出现的规模(来源:arxiv)
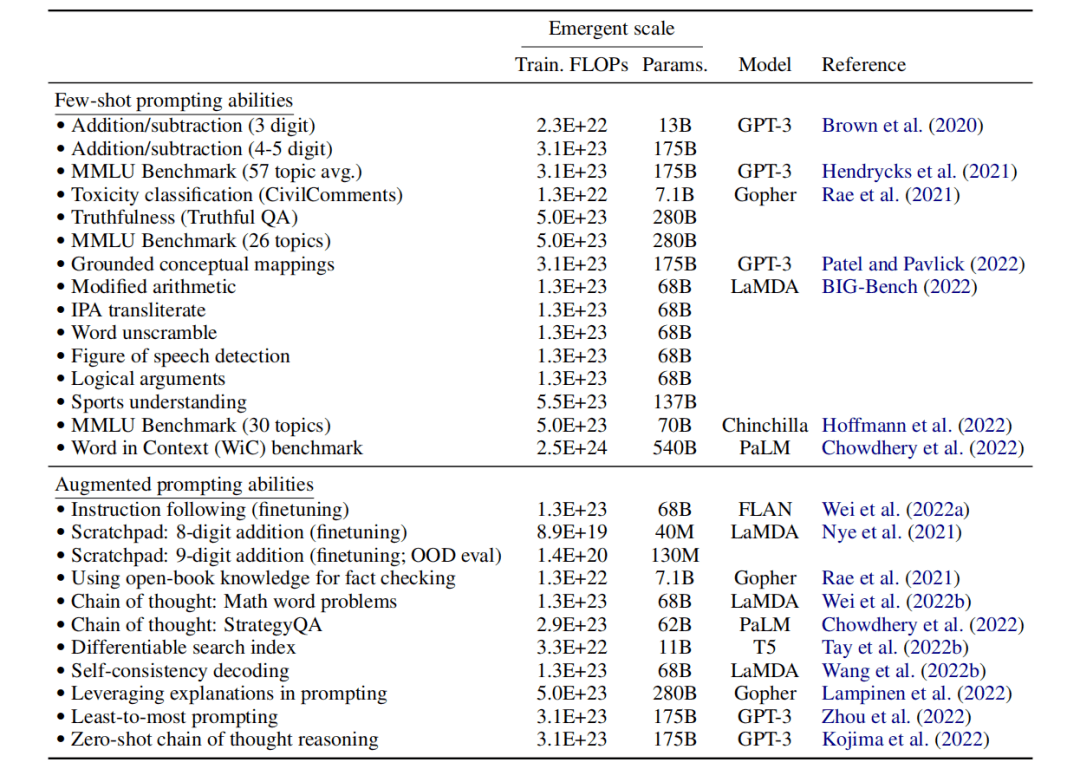
至于突现发生的原因,目前几乎没有可信的解释为什么这些能力会以这样的方式出现。一个可能的解释是,涉及一定数量步骤的任务可能还需要具有相同深度的模型,并且可以合理地假设更多的参数和训练可以更好地记忆,这可能有助于需要世界知识的任务。例如,在封闭式问答中,具有良好的性能可能需要一个足够参数的模型来捕获压缩知识库本身。
另外,用于衡量突现能力的评估指标也很重要。使用精确的字符串匹配作为长序列目标的评估度量,可能会将复杂的增量改进伪装成突现。类似的逻辑也可能适用于多步骤或算术推理问题,因为突现能力仍然可以在许多分类任务中观察到。
研究者还提到,他们本次研究的目标不是描述或声称需要一个特定的规模来观察突发能力,而是讨论之前工作中的突现行为的例子。总的来说,目前还需要更多的工作来梳理是什么使规模能够解锁突现能力。
值得一提的是,模型不是产生突现能力的单一因素,也取决于其他因素,其不受数据量、质量或模型中参数的数量的限制。另外,今天的语言模型可能没有得到最佳的训练,对如何最好地训练模型的理解将随着时间的推移而发展。随着大语言模型训练的进步,具有新架构、更高质量数据或改进训练程序的较小模型,可能也会解锁某些能力。这意味着本研究中的突现能力或其他能力最终可能也可供其他 AI 模型的用户使用。
-End-