中国推出全新预训练深度势能模型DPA-1,对分子模拟产生深远影响
- 发布时间:2025-07-01
- 来源:DeepTech深科技
“DPA-1 模型的提出证明了基于大模型实现‘预训练+少量数据微调’流程的可行性。这是是势能函数生产的新范式,也是未来一系列工作的起点。”对于近期研究成果所具有的重要意义,一支中国团队这样表示。
基于机器学习的预训练深度势能模型正在分子模拟领域发挥着日益重要的作用,与此同时,由于现有的模型迁移能力有限,训练成本较高,对训练数据的依赖性也很强,所以其在实际应用中的表现仍然不尽人意。虽然相关研究人员为了解决这些问题也做出了很多探索和实践,但成效尚不明显。
为了克服上述因素造成的不良影响,解决在分子模拟背景下,面对新的复杂体系仍需生成大量数据来从头训练模型的关键难题,由深势科技(DP Technology)和北京科学智能研究院(AI for Science Institute,Beijing)研究员及合作者组成的中国团队基于新的门控注意力机制(Gated Attention Machanism),推出了通用性较强,能容纳元素周期表中大多数元素的模型 DPA-1。
近日,相关论文以《基于注意力机制的分子模拟预训练深度势能模型》(DPA-1:Pretraining of Attention-based Deep Potential Model for Molecular Simulation)为题在 arXiv 上预发表[1]。
 (来源:arXiv)
(来源:arXiv)
DPA-1 模型是在 DP 系列模型基础之上的全面升级,具有以下优势。
首先,该模型利用与自然语言处理领域注意力机制比较相似的门控注意力机制,对原子之间的相互作用进行了充分的建模,这能使模型在现有的数据条件下学习更多隐含的原子交互信息,可有效提升模型在不同数据集之间的迁移能力和数据生成时的采样效率。
其次,模型中包含了经过编码后的元素,且不同元素用的是相同的网络参数,这有利于拓展模型中的元素容量。
同时,由于模型在拥有 56 种元素的大数据集上开展了预训练,并在多个下游任务上完成了迁移学习,所以能够在保证预测精度的前提下,大大降低训练成本和训练数据量。
此外,该模型还拥有超高的推理效率,可执行大规模的分子动力学模拟。
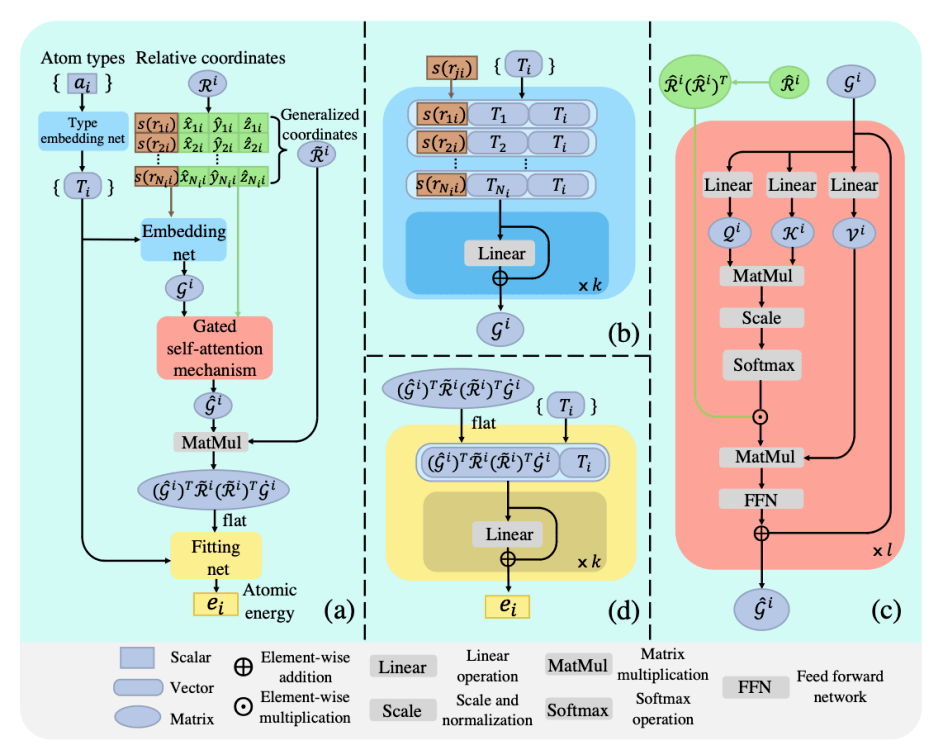 ▲图 | DPA-1 模型示意图(来源:arXiv)
▲图 | DPA-1 模型示意图(来源:arXiv)
为了切实有效地避免传统模型带有的局限性,开发人员开展了几项有针对性的实验。
开发人员先将不同训练集以多子集形式进行划分,然后在训练一部分子集的同时去测试另一部分子集。需要说明的是,这里每个子集之间的构象和组分都不相同,比如,在 AlMgCu 数据集上,single 子集中只有单质数据,binary 子集中只有二元数据,ternary 子集中只有三元数据。
最后,开发人员分别对 DPA-1 和 DeepPot-SE 这两个模型在 AlMgCu 合金、固态电解质(SSE,solid state electrolyte)和高熵合金(HEA,High-entropy alloys)这三类数据集上的表现进行了测试。结果显示,与 DeepPot-SE 相比,DPA-1 的测试精度能达到一两个数量级的提升,这充分说明了后者拥有强大的迁移能力。
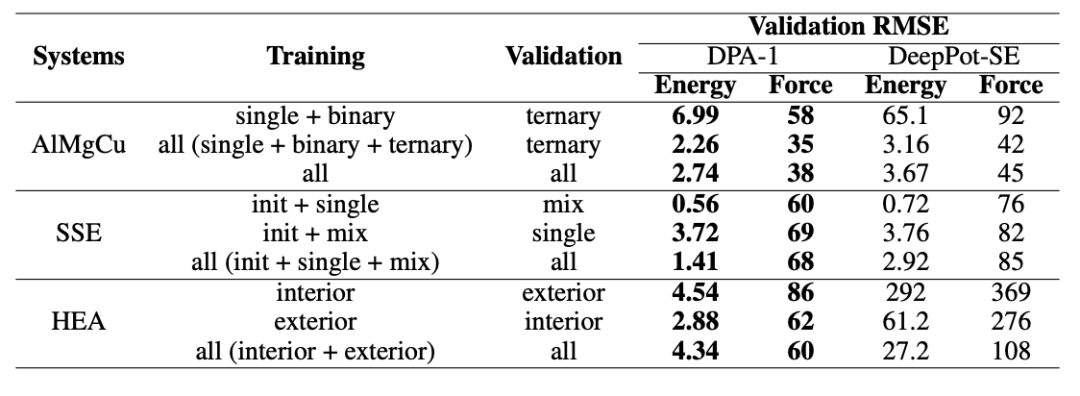 ▲图 | 在不同训练集上测试得到的结果(来源:arXiv)
▲图 | 在不同训练集上测试得到的结果(来源:arXiv)
在“预训练+少量数据微调”的模型生产范式下,开发人员给 DPA-1 规划了一套迁移学习方案。先在大规模数据上开展模型预训练工作,而后借新数据集的统计结果修改最后一层的能量偏差,并将其作为新任务的训练起点。
比如,先在 AlMgCu 数据集中的一、二元数据上执行预训练,并在三元数据上完成测试。紧接着,执行 OC2M 数据集上的预训练工作,再分别迁移至 HEA 和 AlCu 数据集上。结果显示,DPA-1 不仅能在只有三元数据的场景下实现较高精度,还能有效减轻对下游训练数据的依赖。
 ▲图 | 在不同数据集上,DPA-1 和 DeepPot-SE 的学习曲线图(来源:arXiv)
▲图 | 在不同数据集上,DPA-1 和 DeepPot-SE 的学习曲线图(来源:arXiv)
开发人员还将 DPA-1 中已被编码的元素参数进行了 PCA 降维和可视化表现。结果表明,在隐空间中所有的元素都呈螺旋状分布的态势,并且同周期的元素沿螺旋下降趋势分布,同族的元素垂直于螺旋分布,这种分布态势与其在元素周期表中的位置巧妙对应,能够很好地证明模型的可解释性。
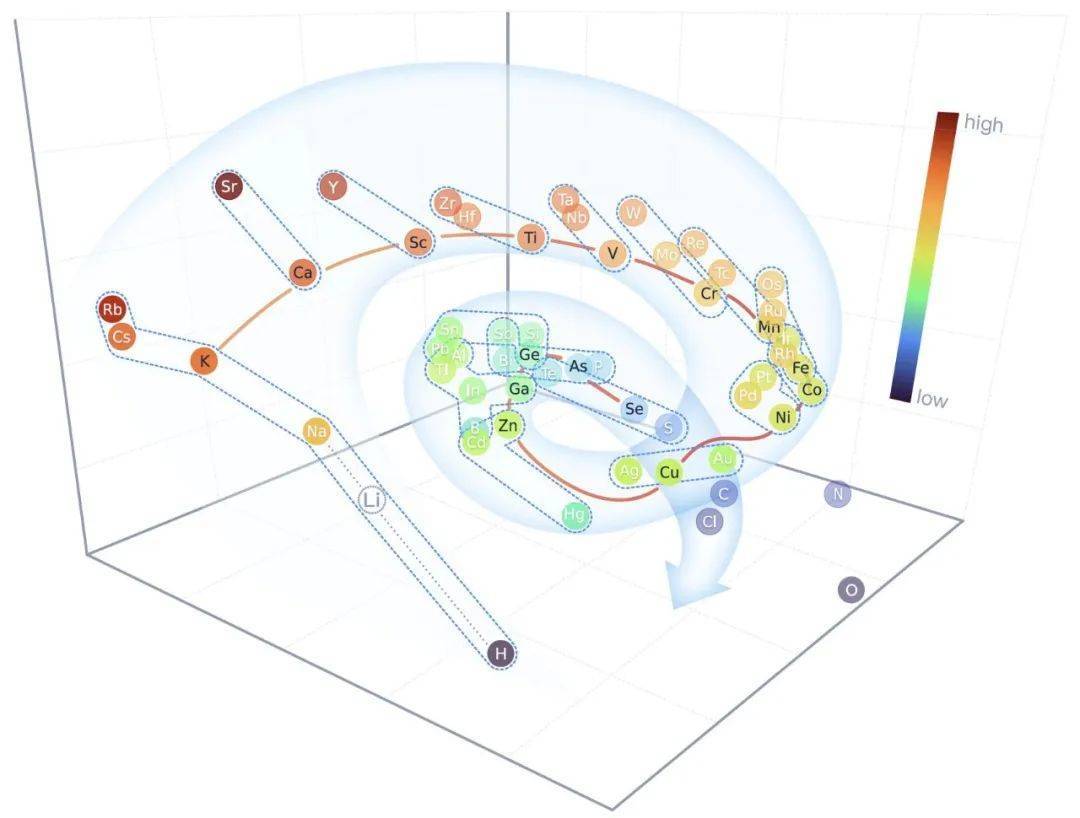 ▲图 | PCA 降维和可视化表现图(来源:arXiv)
▲图 | PCA 降维和可视化表现图(来源:arXiv)
目前,该团队已在其科学计算云平台 Bohrium 上完成了 DPA-1 的开源工作,DPA-1 关于训练和分子动力学模拟功能的开源也已在 DeepModeling 开源社区的 DeePMD-kit 项目下实现。
该团队表示:“未来,我们将继续致力于势能函数的自动化生产和自动化测试研究,仍会继续关注诸如多任务训练、无监督学习、模型压缩和蒸馏等方面的操作。此外,更大更全的数据库、下游任务和 dflow 工作流框架的结合也是着重发展的方向。”
参考资料:
1.Duo, Z., Hang, B.et al. DPA-1:Pretraining of Attention-based Deep Potential Model for Molecular Simulation. arXiv (2022). https://arxiv.org/abs/2208.08236